
Compute Acceleration April 2024
Compute Acceleration April 2024
Big announcements from the likes of Nvidia, Google and Meta

We’ve covered advancements in Compute Acceleration, and their application in biotech, in a few long-form post here. There is more interest than ever in compute, the limitations of it, and their applications, now that we are still riding the wave of the ‘AI hype’.
Nvidia Blackwell and GB200 superchip
The dominant player, Nvidia, announced their new Blackwell architecture, which will come in line soon to boost the compute capabilities already demonstrated by the Ampere and Hopper architectures.

The Ampere architecture, with the A100 GPU as its workhorse, has been the dominant piece of Compute Acceleration in this wave of AI we are riding. The likes of OpenAI have built their shiny new AI products on farms of A100 GPUs, sometimes in the tens of thousands of them. Nvidia a couple of years ago announced their Hopper architecture, and their H100 GPUs as an incremental improvement over the A100 GPUs, and now the likes of Meta are counting their expected Compute Acceleration ambitions in “H100-equivalent compute”.
Earlier this spring, Nvidia announced Blackwell and the GB200 superchip, which will surely be a best seller as demand still strips supply for these type of products.
Google Axiom
Google has had a recent history of “doing their own silicon”, relatively unaffected by the offerings of Nvidia, AMD or other players. Yet Google has a cloud division, Google Cloud Platform (GCP), and for that they do have all sort of third-party offerings in a multitude of configuration.
On their own silicon efforts, Google has kept banging on their TPU work, for Tensor Processing Units. These are AI accelerators in the form of ASICs, which Google started pushing out in 2016, and has continued to do so since then.
These aren’t CPUs, and Google has been relatively quiet about building their own CPUs… until now.
Google Axion Processors are Google’s first custom Arm®-based CPUs designed for the data center. They will be available to Google Cloud customers later this year.

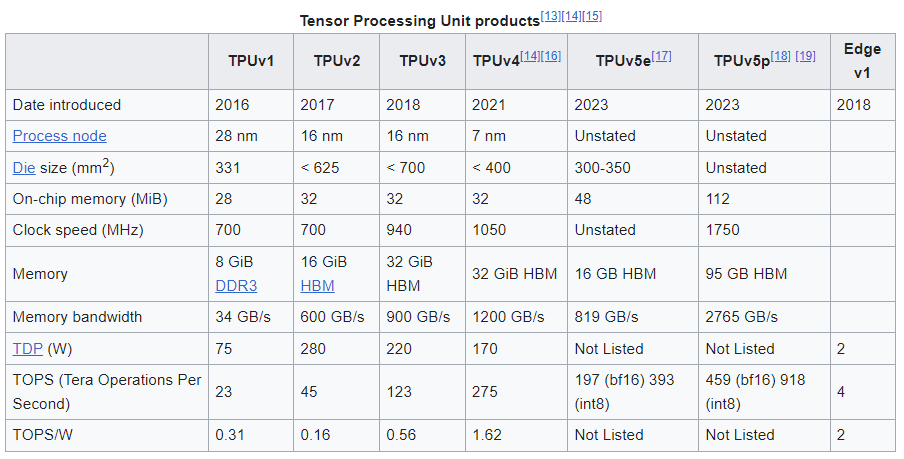
Google explains their silicon journey starting in 2015, with the first generation of TPUs. Then in 2018 they released their first Video Coding Unit (VCU), which didn’t make a big splash, and may only be part of products we consume like Youtube, but has little direct consumer exposure. The “system on a chip” (SoC) versions of the TPU architecture did make it into consumer’s hands in 2021, with the first version of the Edge TPUs on Google’s Pixel line of mobile phones and tablets.
So why work on their own silicon for CPUs if everybody is concentrating in accelerators? Amdahl’s Law suggests that as accelerators continue to improve, general purpose compute will dominate the cost and limit the capability of our infrastructure unless we make commensurate investments to keep up. The same can be said about other parts of computing resources, like IO speeds, both in memory and disk.
For this reason, Google Axiom is Google’s play that follows what Apple did with their own ARM-based silicon in the Apple Silicon line of products for mobile devices and Mac computers, e.g. the M1, M2 and soon M3 chips.
Google claims to have achieved up to 30% better performance with Axiom than the fastest general-purpose Arm-based instances available in the cloud today, up to 50% better performance and up to 60% better energy-efficiency than comparable current-generation x86-based instances. This is another demonstration that the x86-based chips have lacked the flexibility from companies other than Intel and AMD to continue to evolve, having brought us the PC revolution a few decades ago, and are now unable to bridge the gap from large power-intensive chips for PCs and Data Centers into the more nimble mobile chips. The journey in the other direction, from nimble mobile chips, mostly based on ARM-based architectures, have now been able to bridge the gap into the Data Center, and Google Axiom is the latest example of this transition.
Axiom is based on the Arm Neoverse™ V2 CPU, and is underpinned by Titanium, a system of purpose-built custom silicon microcontrollers and tiered scale-out offloads. Titanium offloads take care of platform operations like networking and security. Titanium also offloads storage I/O processing to Hyperdisk, Google’s new block storage service that decouples performance from instance size and that can be dynamically provisioned in real time.
Google Axiom will now be surely compared to what Amazon started a few years ago and delivered their Graviton2 processor, based on Neoverse N1 CPU microarchitecture. The Graviton2 is a 64-core server chip manufactured by TSMC’s 7nm process node. Neoverse V2 claims higher performance gains compared to Amazon’s Graviton2 which is based on Neoverse N1. They are different, but not that different: both are part of a broader industry trend towards adopting ARM-based processors for cloud and data center environments, driven by the need for more energy-efficient and high-performance computing solutions.
Meta Training and Inference Accelerator
Meta also announced silicon developments in their AI journey with their new Meta Training and Inference Accelerators (MTIA).

This latest version shows significant performance improvements over MTIA v1 and helps power Meta’s ranking and recommendation ads models. This new version of MTIA more than doubles the compute and memory bandwidth.
In inference, Meta focused on providing outsized SRAM capacity, relative to typical GPUs, so they can provide high utilization in cases where batch sizes are limited and provide enough compute when experiencing larger amounts of potential concurrent work.
This accelerator consists of an 8x8 grid of processing elements (PEs). These PEs provide significantly increased dense compute performance (3.5x over MTIA v1) and sparse compute performance (7x improvement). This comes partly from improvements in the architecture associated with pipelining of sparse compute. It also comes from how Meta feeds the PE grid: they have tripled the size of the local PE storage, doubled the on-chip SRAM and increased its bandwidth by 3.5X, and doubled the capacity of LPDDR5.
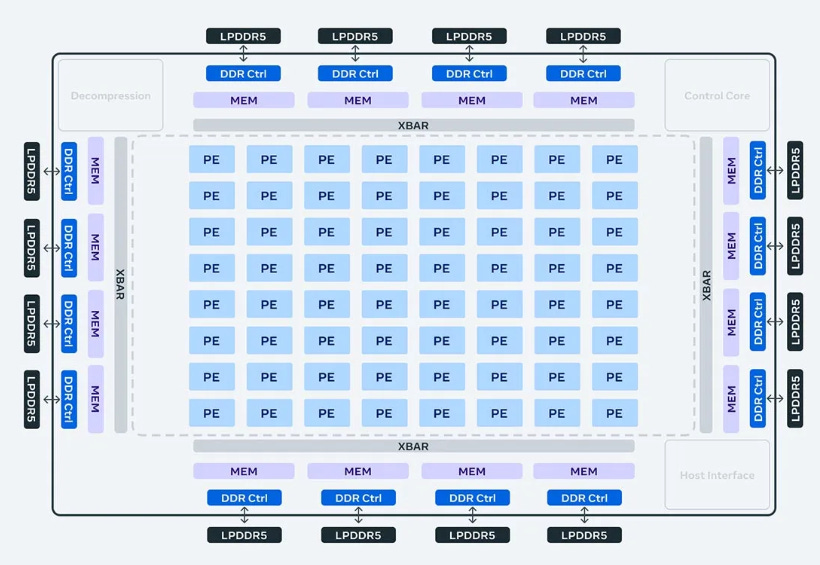
The Next Gen MTIA is also based on TSMC 5nm fabrication, compared to the 7nm equivalent of First Gen MTIA.
In the section below, I’ll comment on the aspects of these news that touch upon biotech companies I track, such as Recursion Pharma RXRX 0.00%↑ .